
How languages influence each other and evolve

What starts as a good idea in one place often ends up as a good idea in other places. There’s plenty of examples of this, from API design, to language features.
One such example which is interesting to look at is list comprehensions - a concept that didn’t even begin life as a programming concept, but then was added early on into some languages known for inspiring others, and then became a popular concept.
It’s also interesting to look at languages which haven’t adopted this, and why. Not all languages should adopt every idea, and not every language should have the same implementation. Selective design takes ideas from many sources, filters out the irrelevant ones, and adopts those that fit the principles of the language. These concepts apply to all aspects of tech: from product design, to API design, to language design.
Let’s take a deeper look at list comprehensions.
A disclaimer before we get started: I’ve included a rough timeline, but can’t cover every language. So I’ll cover enough distinct languages to point out some interesting points. Don’t be offend if your favourite language is left out!
What is a list comprehension?
List comprehensions allow a developer to write list manipulation succinctly, without needing to manually modify the list after creation. It originally came from maths, but became popular in immutable languages like Haskell. From there, other languages adopted comprehensions - sometimes adapting them for other purposes, too.
A basic example might look like:
[ greet(user) for user in users if user.name == "Noah" ]whereas a more traditional for-loop would look like:
greeted_users = []
for user in users:
if user.name == "Noah":
greeted_users.append(greet(user))The list comprehension in this example didn’t need to call .append, and could be expressed in one line.
Let’s take a look at why some languages have adopted this, and others haven’t.
The problem statement
We’d like to take a nested list of user objects, and extract the name of any users which are 30 years old. Imagine that the user objects are something like:
type User = {
first: age,
second: name
}The pseudo-code to then process the list would look like this:
output_list = []
input_list = [
[
{ "age": 29, "name": "Joan" },
{ "age": 30, "name": "Dave" }
],
[
{ "age": 30, "name": "Harry" },
{ "age": 35, "name": "Sally" }
]
]
for sublist in input_list:
for user in sublist:
if user.age == 30:
output_list.append(user.name)
print(output_list) # [ "Dave", "Harry" ]Let’s take a look at how these can be expressed in some languages1, starting at the root: mathematics.
Maths
In set theory, there’s a syntax called set-builder notation. If we adapt it a little bit to fit programming, it looks something like this:
In maths, it’s quite common to want to express some logical concept in as few characters and as many symbols as possible. Set builder syntax allows for the simple representation of a complex set relation.
This concept and syntax were adopted by programming languages, with an origin in 1970s with languages such as ML, Miranda, KRC, Id. NPL, a language appearing in 1977, was the first with comprehensions, operating on sets rather than lists. Id introduced array comprehensions in 1978, and in 1982, list comprehensions (then known as ZF expressions) were introduced in a language called KRC.
💡 Interesting 💡: Set theory lacks a traditional debugging step that we have in programming languages. How might you inspect input_list, or sublist to check their values? This is interesting because list comprehensions in other languages are often hard to debug, as there is not a natural point to put a break or print expression. New comers to list comprehensions will often print the values before the comprehension, and after, but not during. Many early language adopters of comprehensions were lazy — values were only calculated as they were needed by the program, which matches the theoretical application of set theory.
Haskell
While other languages did have list comprehensions before Haskell, Haskell is really where it became popular as a concept that then spread to other mainstream languages. In the first Haskell specification2, list comprehensions looked like this:
[ x | xs <- input_list, User { name = x, age = 30 } <- xs ]The most popular Haskell compiler, GHC, has many language extensions which add many new features to Haskell code. There’s a few for comprehensions, with the three most notable being generalised list comprehensions, parallel list comprehensions, and monad comprehensions. Generalised list comprehensions add a SQL-inspired syntax, while monad comprehensions generalise the ability to map and filter over any monad. Note that lists are a monad, so it is not strange to provide monad comprehensions - something that other languages would follow suit in doing, too.
💡Interesting💡: Haskell’s syntax is close to the set theory origins, and has language extensions that provide alternative syntax and broader scope. Haskell’s influence took an idea from smaller, experimental languages, and made it notable with the mainstream language community.
Python
Python introduced list comprehensions in 2.0, through PEP 202. Python’s version looks a lot like a regular for-loop, but condensed with inline ifs.
[ user["name"]
for sublist in input_list
for user in sublist
if user["age"] == 30
] PEP 274 then introduced dict and set comprehensions to Python 2.7 and 3.0, allowing for succinct ways of creating dicts and sets. Interestingly, this was originally proposed for Python 2.3, but dropped in favour of generator expressions with the dict() function constructor. The fact that this was reintroduced, with the exact same proposal, and accepted, is a good reflection of how long term language development happens. An idea might not seem as good as alternatives in the past, but with more information on usage and code style, it may become more attractive.
After generators were introduced in PEP 255 (Python 2.2), generator comprehensions were added with PEP 289 (Python 2.4). After async/await support was introduced with PEP 492 (Python 3.5), async comprehensions were added with PEP 530 (Python 3.6).
💡Interesting💡: Python was the first mainstream language to add list comprehensions, so many developers know comprehensions from Python, rather than set theory or Haskell. Comprehensions have become a standard way of interacting with data in Python.
C#, DotNet
C# added LINQ in version 3.0, which provided powerful ways of doing comprehensions - including lists. LINQ support was added via the .Net framework, so other languages using it could implement their own LINQ integrations (e.g Visual Basic). LINQ came out of Microsoft’s language research producing Comega, a language focused on researching data querying and manipulation. LINQ is very powerful, it might be the most powerful implementation of comprehensions on this list. The syntax is quite distinct from the C# or Visual Basic it is contained in. This is an example of a DSL being a core language feature.
from sublist in input_list
from user in sublist
where user.age == 30
select user.name💡Interesting💡: Other .Net languages like Visual Basic also have support for LINQ - it’s a language feature built into the .Net framework which is then exposed through each language’s syntax. LINQ is also one of the most comprehensive comprehension implementations.
JavaScript
JavaScript’s never had list comprehensions as part of the standard spec, but browsers used to implement their own extensions to the language. Firefox had list comprehensions for a while, but dropped them when they weren’t considered for ECMAScript 7. The Firefox implementation looked like this:
[ user.name
for (user of sublist)
for (sublist of input_list)
if (x.age === 30)
]When tc39 met in June of 2014, they decided to defer adding comprehensions so that they could be generalised. When they then met in July, they looked at some theoretical implementations of code using different styles, one Python-style, one LINQ-style, and the other using regular function calls. The discussion focused around generators and the need for array-like operations on them (e.g filter, flatMap). Comprehensions were shelved until the next version of ECMAScript, and not brought up again. Generators still don’t support these operations, either. Perhaps this is a reflection of JavaScript’s usage in browsers, where datasets tend to be smaller than on the backend. A list comprehension in Python could potentially deal with huge amounts of data, which would not make sense to exist in a browser.
The pure JavaScript version looks like this:
input_list
.map(
(sublist) =>
sublist.flatMap(
(user) => user.age === 30 ? user.name : []
)
).flat()ECMA does not often add new syntax to JavaScript. Functions are added to the standard library with each release, but new keywords are rarely added. I think the last added keywords might be async/await in ES2017.
💡Interesting💡: JavaScript rejected comprehensions, in favour of API methods. One implementation of non-spec JavaScript (Firefox) did once support comprehensions.
Ruby
Ruby doesn’t have list comprehensions, though it’s been raised in the community sometimes. Like JavaScript, the Ruby approach is to stick to a commonly used pattern - chaining list map/filter function calls.
input_list
.map { |sublist|
sublist
.select { |user| user.age == 30 }
.map { |user| user.name }
}
.flatten💡Interesting side-note💡: Ruby’s naming for filter (select) is my preferred name for a function that does (a → boolean) → List a → List a. Unlike filter, select describes the action - selecting values that match a condition. filter could mean “keep all values that match” or “remove all values that match”, depending on who you talk to, especially for those new to programming.
Erlang and Elixir
Erlang’s comprehensions support multiple different data types as the source, and have had many improvements, like tuple support, and map support. Since Erlang uses recursion for control flow, building a list otherwise would require recursive logic. The comprehension format allows an immutable list to be created without recursion.
[ user.name || user <- sublist,
sublist <- input_list,
user.age == 30
]Elixir has list comprehensions as part of the normal for syntax, again simplifying list building.
for sublist <- input_list,
%{age: age, name: name} <- sublist,
age == 30,
do: name💡Interesting💡: Since both Erlang and Elixir are BEAM-based languages, it’s interesting to see that the syntax for the user differs, with for being used more generally in Elixir while Erlang would use recursion.
Java
Java’s approach is much like JavaScript and Ruby: instead of adding custom syntax and keywords, Java added Streams in 1.8. Since stream APIs rely on passing functions to .map/.filter, there was a need for a way to create functions without the prior overhead of functions, so lambda expressions were added in the same release.
The code ends up looking something like this in Java flavour pseudo-code:
widgets.stream()
.map(sublist ->
sublist
.filter(user -> user.age == 30)
.map(user -> user.name)
)
.collect(Collectors.toList())💡Interesting💡: Java is often used for heavy data processing, so the stream interface provides a way to interact with data that can be optimised. Rather than change the syntax to introduce list comprehensions, Java added lambdas which have multiple uses for small, short lived functions, with a broader application than comprehensions alone.
Elm
Elm does not support list comprehensions, citing a lack of need for them in a language which has map/filter support. This argument is similar to the ones followed by JavaScript, Ruby, and Java.
input_list
|> List.concatMap (\sublist ->
List.filterMap (user ->
if user.age == 30 then
Just user.name
else
Nothing
)💡Interesting💡: Despite being an ML language family, Elm deviates from comprehensions in favour of function calls.
Timeline
This is my attempt at putting together a rough timeline with different branches showing how ideas crossed between languages, but it’s not perfect. Feel free to make a revision on the gist for it here.
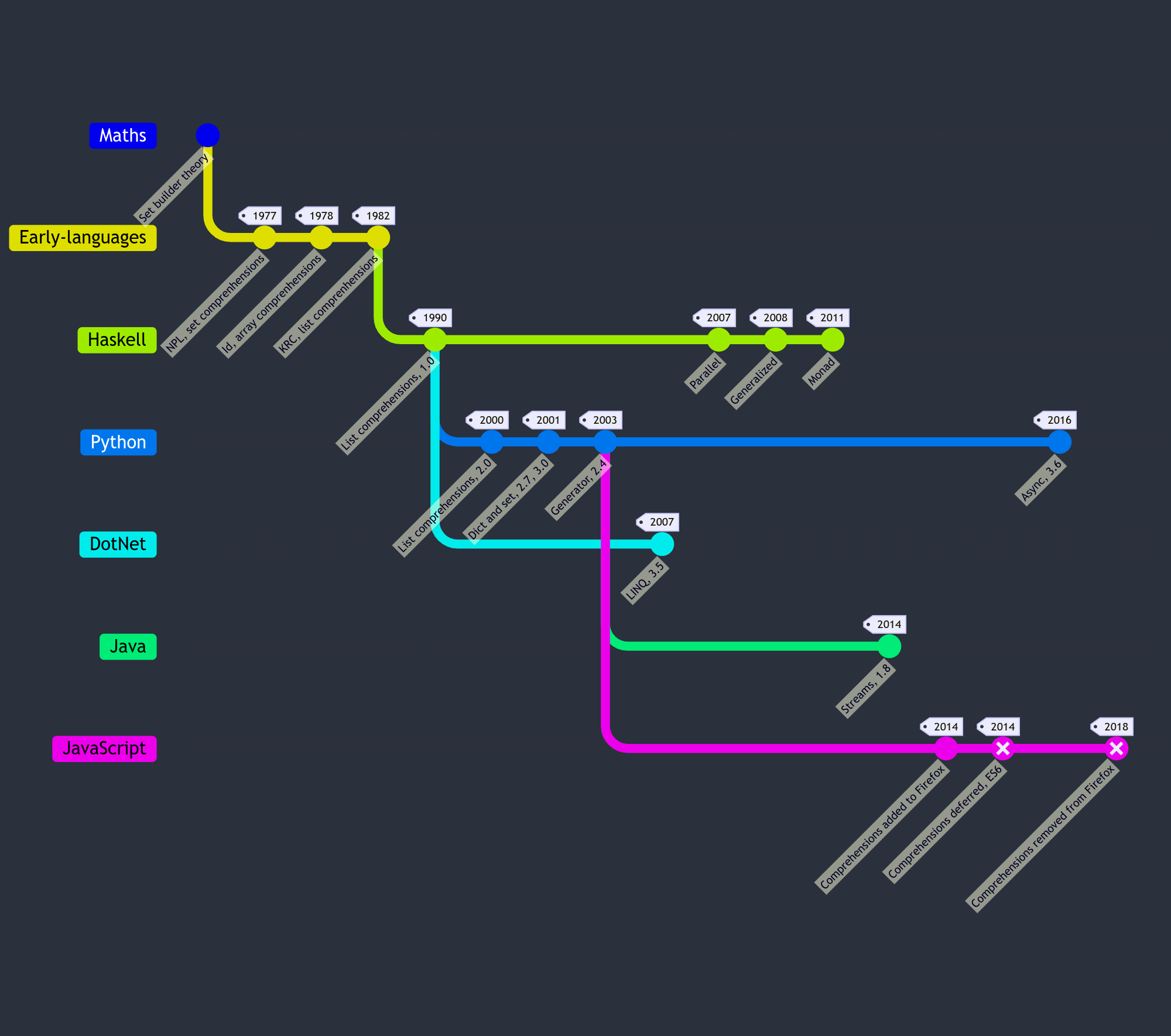
Adding new features to a language
Language designers for stable languages have to think about the future: any added syntax complicates the parser, the language itself, and adds one more feature that the language will need to support until a breaking change release. APIs can deprecated or moved out of the standard library, but syntax must be supported or code won’t parse. Why introduce new, unfamiliar, syntax to developers when existing patterns (like chaining .map/.filter) can be applied and developers only need to learn a new function, something they do every day?
Python already had for loops, but preferred not to use functional practices like maps and filters, list comprehensions filled a gap in the language. On the other hand, languages like JavaScript, Ruby, or Java had already established APIs that avoided the need for loops, so it makes total sense to not add such a feature.
These principles can be applied to all design, whether it’s language, API, or product. If you add a feature:
Does it provide value?
Will it be worth the cost of maintaining it?
Will users use it as you expect?
Will it fragment your community?
Other examples
List comprehensions far from the only place languages have developed and shared new ideas. It’s very rare for a concept to be entirely novel, and those novel ideas often start in small experiments rather than established languages.
Some good examples from recent years:
Result union types (a type of either an Ok value, or an Error message)
Optional union types (a type of either Just a value, or Nothing)
Async / Await (syntax for handling asynchronous code in a similar way to synchronous code)
Type inference
Standardised Code formatters
A future idea I’m excited about
I’m particularly excited about typed holes, which have already found their way into Idris and Haskell among others. I think we’ll see a similar adoption to type inference in a few years, making it easier for both developers and tooling to help augment the gap between types and implementation. Pair that up with more powerful generative AI tools, and you may be able to have type-safe, valid, code generated that actually fits what you were trying to do.
Closing
This article came out of some discussions I’ve been having lately, along with some sidenotes I made from my post on mainstream languages I would use in production in 2024. The next article in the “things I recommend” will be about niche languages, where this concept of language learning and development is much more relevant, as niche languages have more freedom to choose experimental features.
In summary
Projects of all kinds are often independent and unique, but that doesn’t meant they don’t share ideas, concepts, or code. If you’re looking to improve anything you do, it’s always valuable to look around to see what others are doing. Maybe you’ll come up with something nobody is doing, but it’s far more likely you’ll find something others are doing, but adapt it to your user case.
If you liked this post, feel free to share or subscribe, and don’t be afraid to reach out to me!
Some of the language code snippets below are near-enough rather than exact code.
Haskell Report 1.0
You missed a BUNCH of influences that F# has on many other languages. It's all here... LINQ in particular being influenced by Haskell is fairly well known, but he it's worth following the thread on where async and reactive extensions (Rx) came from.
https://fsharp.org/history/hopl-final/hopl-fsharp.pdf