

Your problems probably aren't as unique as you think they are
Your problems probably aren't as unique as you think they are
But that doesn't mean you shouldn't have rewrites, or create new tools to solve old problems.

A common notion I often see is that every team consider their problems to be unique to them, requiring unique solutions. While there’s definitely often subtle differences in context and application, the implementation usually doesn’t need to be new or novel. Yet programmers are intent on rewriting, rebuilding, and reimplementing. I’m prone to it myself. Sometimes this can be a problem, so what can be done to deal with it?
The majority of products that developers work on don’t need fancy approaches. Either their problem space is a common one encountered by others, or they don’t need clever solutions to solve the users’ needs. Libraries help cut down code re-implementation. Frameworks can reduce the amount of infrastructure code required, but in other cases they can complicate the sharing of solutions.
To prevent the urge to rewrite everything, developers need to be comfortable relying on the tools and stacks they use. This comfort doesn’t mean they write everything using existing libraries or frameworks, but it means they know where and when to use them.
Fear of the unknown
A large, complex, codebase triggers concern in developers. As a codebase grows to handle all the needs of the users, so too does the cognitive load. If something can be written in 100 lines of code where a developer knows how each part works, 30 lines of code using a framework which does unknown things can introduce fear. Why branch out and depend on a framework with thousands of commits and hundreds of contributors, when it could all be written by one developer in 3 commits?
Perhaps the developer has been burnt by libraries before. There’s plenty of examples of this:
Hard to debug bugs, frustrating the development process.
Security issues, disappointing the team.
Complicated dependency reliance, introducing complexity.
Not solving the problems the user has, blocking feature development.
Fearing the unknown is not a bad thing. It’s good to be cautious. However, if the solution taken is for the developer to write everything themselves, and not to understand existing tools, costly rewrites become the norm.
Frustration of the known
Once a developer has enough experience with a particular stack, they’ll find edge cases where it doesn’t work the way they want or need. The more edge cases they encounter, the more likely they are to want to rewrite. This is true of their own code just as much as other developer’s code that they use. Small rewrites often take place as refactors, while larger rewrites might completely start from scratch. It’s healthy to refactor code, but larger rewrites come with a time and effort cost. Given enough time, the chances for a complete rewrite increase. I’d even go as far as to say that it’s inevitable.

Two aspects of developer passions
This is a sweeping generalisation, so take it with a grain of salt, but it seems mostly accurate to me.
I’d like to talk about two aspects of developer passions, a drive to solve end-user needs (e.g the users of your apps or websites), and a drive to solve technical problems (e.g infrastructure, testing, reliability).
The end-user solvers may prefer to spend their time on improving the experience of the end-user in very direct ways: interfaces, app performance, flows. These developers will prefer to use common tooling that minimises the time they spend on background tasks. If given the freedom to choose between a new feature or refactoring, they would likely prefer a new feature. Working on features can be rewarding in way technical debt isn’t: it’s visible, and end users get to use it directly. An example of where they may try to be more unique than needed could be changing the frontend framework from React to Svelte: is switching from React to Svelte justified when the code could’ve been written as easily in React?
The technical solvers may prefer to spend their time on the internals of a product: communication between services, scaling performance, and libraries or frameworks for developers. These developers will prefer to write their own code, which is sometimes thought of as “our code is the product”. It’s rewarding to create useful infrastructure: common problems become simpler to solve, even if the solution is not directly given. An example of where they may try to be more unique than needed could be deployment of services: is having many micro-services running across k8s justified when a singular service running on Heroku could serve the needs?
Both passions of developers are crucial for a product to be successful. Too much time spent on creating new features means old code gets neglected, and often re-implemented without need. Not enough time spent scaling services leads to poor performance. Only focusing on technical debt means no end-user facing features get made, which can make the business goals of the product difficult.
It’s not just developers
Developers are prone to thinking their product is more unique than it is, though they are not the only parts of a company prone to that way of thinking. Consider, for example, streaming services. Video playing on computers has been somewhat standardised for years: spacebar to pause, double click to enter or exit fullscreen, f to enter fullscreen, Esc to exit fullscreen, c for captions.
Yet streaming services haven’t standardised at all, despite users being drawn to their service by the content, and not the player. Nobody is saying “I’ll use Y because of the player”, they’re saying “I’ll use Y because they have the show Z that I want to watch”. I don’t know what went into the decisions that led to some players quitting the playing video when hitting Esc or spacebar. It’s a perfect example of where one video player could’ve been adopted across each platform, with minimal changes, saving the development time considerably, and providing a consistent user experience. Each service does want to seem unique to establish brand loyalty, but focusing on making the streaming experience as good as it can be is the place to start.
Some services provide a stronger experience on top of the video player, like higher video quality or metadata about actors in the scene. This is where I would suggest product development focuses: establish the core product based on industry standards, but provide new features or experiences as extensions. Unless the product is revolutionary, and that’s the core selling point, then product development should be iterative.
When do rewrites become problems?
Developers will pick up a library or framework if it solves a problem they don’t have time to solve themselves. They’ll avoid a library or framework if it looks too complicated to use, or doesn’t solve their use case. They’ll move away from a library or framework when they get frustrated with how it works.
Consider two thresholds:
The point at which a problem becomes too hard (or boring) for a developer to want to solve themselves
The point at which a tool a developer uses causes enough frustration to move away or write their own solution
When threshold 1 is crossed, developers reach out for new tools - libraries and frameworks. When threshold 2 is crossed, a rewrite will happen soon. Neither of these are problems alone, but when a developer gets frustrated and doesn’t consider existing solutions, then a potentially painful rewrite happens. The developer misses the context of the existing tools.
Why is this painful? The tools that already exist were built with a problem in mind. A problem that the developer might not be facing exactly, but there’s likely a lot of useful knowledge to be gained from understanding the implementation, architecture, and edge cases in the existing tools.
This is an approximate visualisation of how I see it often play out:
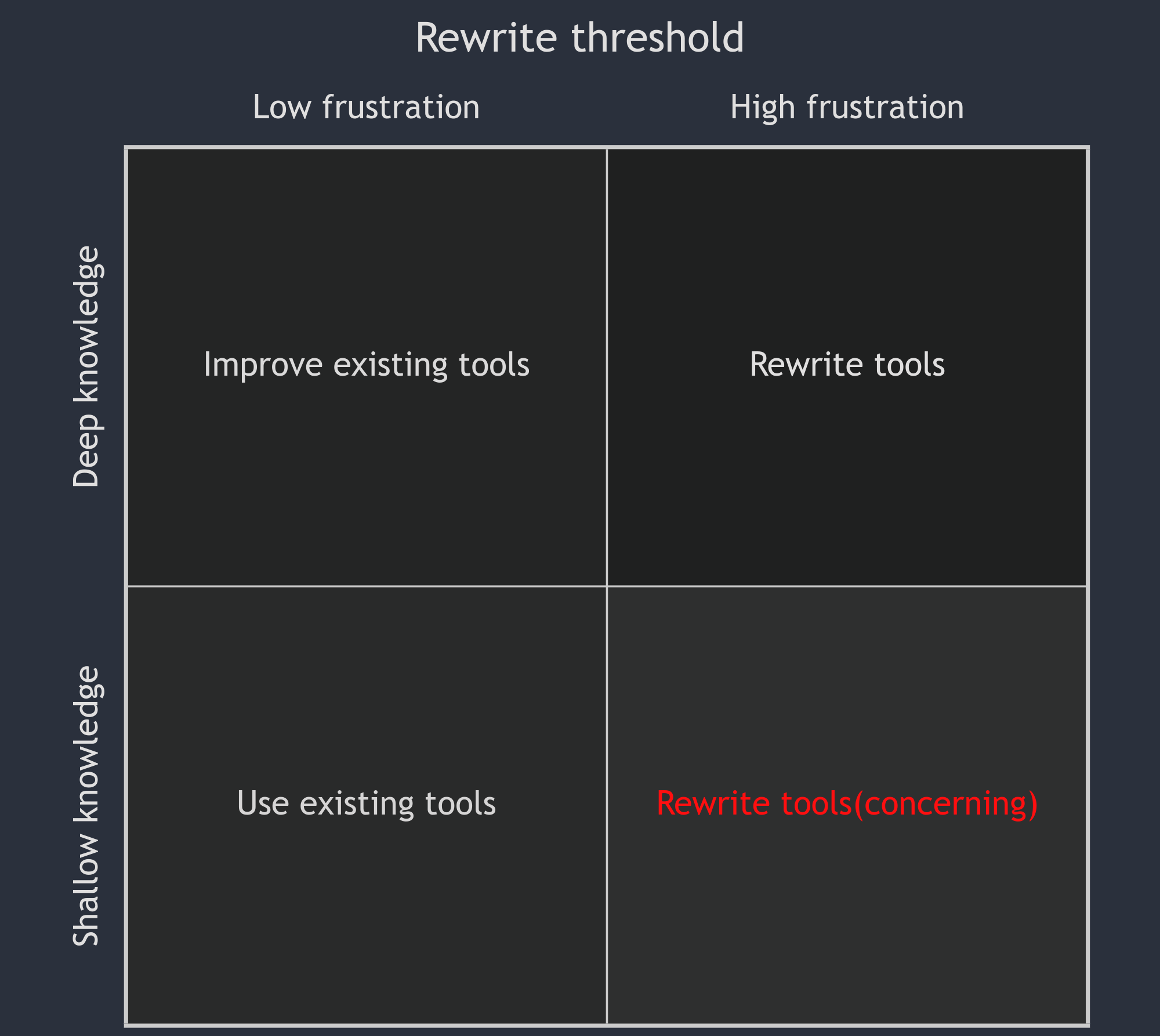
What should developers think about before a rewrite?
There’s a few things to think about, and it’s almost all to do with knowledge. Do everything to understand your problem space, and the existing solutions.
Do you understand the existing tools well enough?
Do you have edge cases which aren’t possible to solve with the existing tools?
Does your team have capacity for it?
Do the gains of the rewrite justify the cost?
Begin with prototypes and experiments, and be sure to give existing tools a fair chance. When a problematic edge case is found, document it and any workarounds you may find. These will be the implementation notes that can shape the rewrite.
Embarking on the rewrite
Once you’ve started the rewrite, prepare for it to take much longer than expected. Even if you are deeply familiar with the existing tools, there’ll be new edge cases to face. Most of the time, you’ll want to focus on small pieces of the existing tool at a time, so that the existing code you have doesn’t stop being useful. However, be aware that there’s a real risk of ending up supporting both the old tool and the new tool indefinitely. Set a deadline for a switchover, and actively work towards it.
Don’t be afraid either to revert to the current stack. If you’ve got enough prior knowledge, and planned the tool replacement well enough, you probably won’t need to do this. But if there’s signs early on that it doesn’t solve the problem you intended, revert.
To get stakeholders on board, demonstrate the potential a rewrite may have.
Typically, if it’s code-only and not features, a rewrite may enable your team to produce higher quality features and design changes easier.
Provide examples of tasks which are costly and complicated today, and how they’d be solved in the new tool.
Dealing with old tech debt may fix debugs or remove limitations.
Security problems might be solved by being up to date with the newer tools.
What can library or framework maintainers do?
Reducing “fear of unknown” for the potential user will make them more likely to use other developer’s code. Reducing “frustration of the known” will make users less likely to switch to something else. As a tool creator, you’ll want to reduce fear and frustration.
There’s a few ways to do that, and here’s some I recommend:
Time to first code
To make a tool appealing, consider the “time to first code”. Wherever they first encounter the tool, the amount of time it takes to get to see some working code should be small. If they’ve arrived at the README, code snippets should be either directly there, or with a clickable link to a relevant example and docs. The code shouldn’t be any random code, though. It should demonstrate how the tool solves the problem it is intended for.
For example, in TypeScript-style pseudo-code:
const maybeUser: Result<User, string> = await wrapResponse(
getUser(123)
);This doesn’t qualify as a good enough example for the entry point. It shows how to use wrapResponse and Result, but not why you’d want to use this over directly calling getUser. It’s good enough for API documentation, but not as the introduction. Let’s expand the code with an example of how Result is useful.
import { wrapResponse, Result, Err } from "my-library";
/**
* @returns a result containing either Settings, or an error message
*/
async function getSettings(): Promise<Result<Settings, string>> {
// exceptions are wrapped so that they're handled at the type level
const maybeUser: Result<User, string> = await wrapResponse(
getUser(123)
);
// exhaustiveness is enforced by the library
// making sure you handle both cases
switch (maybeUser.kind) {
case "Ok": {
return await wrapResponse(getUserSettings(maybeUser.value));
}
case "Err": {
return Err(
`Failed to fetch the default user due to:\n---> ${
maybeUser.error
}`
);
}
}
}It’s possible to go one step further, and directly give users code where they can see the problems they currently face with their current approach.
async function getSettings(): Promise<Settings | string> {
// the type system doesn't force you to remember to .catch
return await getUser(123).catch((e) => {
return `Failed to fetch the default user due to:\n---> ${
maybeUser.error
}`;
}).then(getUserSettings).catch((e) => {
return e;
});
}
async function getSettingsWithoutCatch(): Promise<Settings | string> {
// the type system doesn't force you to remember to .catch
// now the logic has to be handled by a try..except block
// at the higher level
return await getUser(123).then(getUserSettings);
}
const settings = await getSettings();
if (typeof settings === "string) {
console.error(settings);
process.exit(1);
}
console.log(settings);
process.exit(0);The closer to a real world use case the code is, the better it is at conveying the message.
Expose clean interfaces, hide complicated code
While the tool might solve a complicated problem, the user shouldn’t have to be exposed to it. If the public API is too restrictive, then it’ll frustrated users as they won’t be able to solve the problems they have. If it’s too permissive, users can end up in odd code that the maintainer didn’t intend. An API that has too many options or endpoints will overwhelm the user. Focus on the core problem, and if there’s use cases that don’t fit, document them. In other words, make the most common problems easy, document the edge cases.
Be honest about limitations
If the tool fits a particular use case best, be explicit about it. If it intends to cover other use cases in the future, provide a way for potential users to reach out. Issues, mailing lists, chat, it doesn’t really matter - pick one, and stick to it. Make sure that the conclusion from discussions is searchable for any new potential users who may have similar questions.
Share reflections on implementation details
Other, competing, tools will come up, even if your tool currently dominates the user share. Don’t fear this, embrace it, and speak openly about challenges you’ve faced and lessons you’ve learned. These ideas are as powerful as code.
Make switching to and from your tool possible
If a tool requires a heavy investment to adopt, then two things become true:
Users will be reluctant to adopt, due to vendor lock-in.
Users will stick to your tool even if it doesn’t fit their use case, as the cost to migrate is too high.
Both of these hinder adoption and the community. A classic case is when a framework requires considerably different code from the normal code for the language (e.g domain-specific languages, DSLs). Users will stick to the framework, and become frustrated and disruptive in the community. Others won’t even adopt it.
As a result, if the framework doesn’t considerably benefit from the considerable drift from normal, it’s probably best to stick to normal looking and functioning code.
A good example of where this is done well despite language lock-in is tools like 2to3 or the Swift migrator tool, which migrate code between versions.
Conclusion
So, to sum up:
Rewrites are common, and frequent
Rewrites are problematic when they ignore prior art
Understand the scope of your problem
Look at others who have solved problems in your space
Acknowledge the context of existing solution
Choose “boring” options for the core technology, innovate on top of that
Produce well-documented tools that are refined and concise
Rewrites are costly, but they frequently happen. If they didn’t, the industry would never move forward, and new technology wouldn’t exist let alone be adopted. Prepare for them, accept them, and rewrite the most useful parts to rewrite.